On the latest project I worked on we had regularly running end to end tests making sure our public APIs are up and available; it proved itself useful several times by catching bugs early that were not detected by the unit or integration tests - we even connected it to our alerting as well, to let it detect issues before our users do.
However, after doing that we realized that we are getting a lot of false positive alerts - not because the service had issues but the environment we used for running the tests were not designed for this purpose. The Jenkins instance we had was intended to be the tool for building and deploying services - best-effort availability, often overloaded - and thus not ideal for executing something on which we could rely on as a highly available sentinel watching over our service.
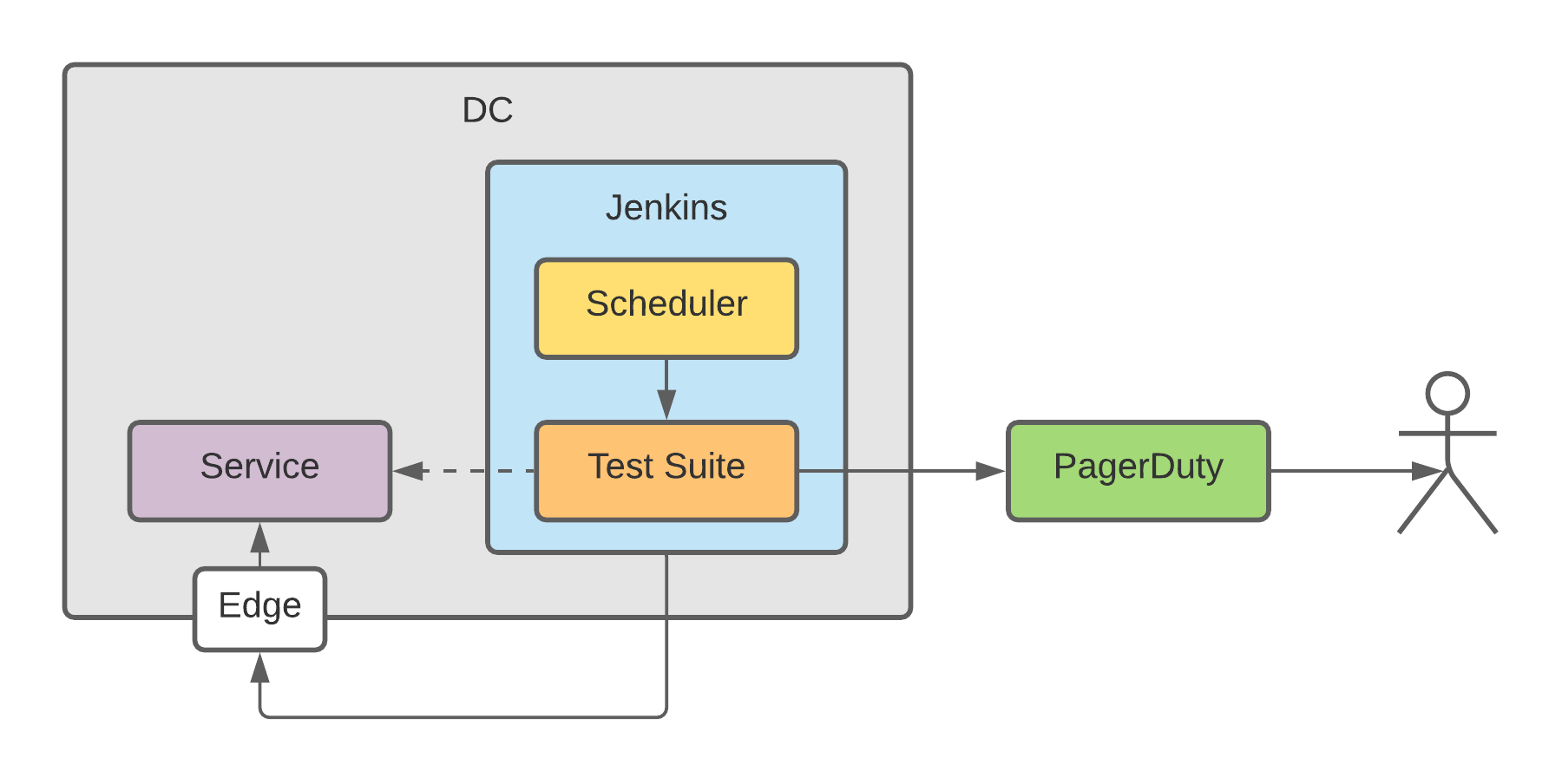
In this post we will look for a better alternative for this setup.
Redesigning the environment
Since are looking for a better environment, we can address the other big issue we have with the current setup: it’s “too close” for the production system.
It is always a good idea to separate the environments responsible for running the production service and the testing service as well as possible. By doing so we can decrease the impact of a component failure both the service and the test suite relies on. You should never underestimate the impact of this; two systems can have some shared resources you’d never think of: like a common ISP, same power source in the data center or a shared repository of Terraform configs. A small issue in any of the shared resources won’t just disable your service but it could disable your alerts about outages as well.
Since in this example our services are running on several private data centers with no strings attached to AWS, running our tests there seems like a good idea.
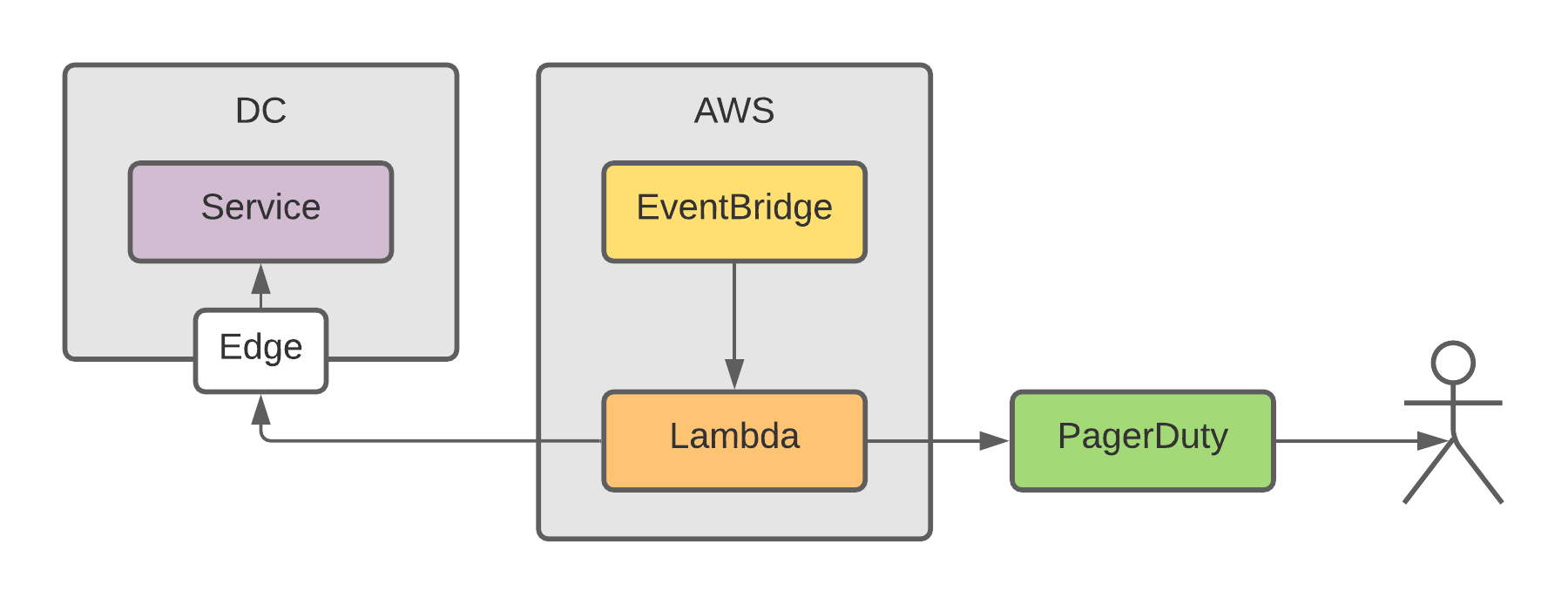
With this new setup we provide a solution for some current issues:
- Jenkins overload or restarts do not affect the test running any longer, we can use it for it’s original purpose: building and deploying services
- We are closer to an actual use scenario, getting calls truly out of our infrastructure, just as a user would do
- The scheduler is separated from the test executor; this is the smallest of our concerns but our schedule job did crash sometimes on Jenkins.
Strict separation of environments also prevents engineers to cut corners in testing code, like calling internal APIs to validate the changes in the data we requested on the public API; while it might be a reasonable thing to check, it is not the responsibility of an end to end test to do so. If you cannot validate the result of an operation on the public API then you probably trying to test something you should not (or using the wrong type of testing).
Setting up the new environment
For running the tests a lambda function is ideal and cheap: it can scale with the complexity of the suite and we pay only for the time while our suite is running. We can use the following command to create the lambda function:
aws lambda create-function
--function-name "arn:aws:lambda:eu-central-1:123456789012:function:e2e-suite"
--role <IAM role for this lambda>
--runtime "go1.x"
--handler "main"
For scheduling a periodic execution we can use EventBridge:
aws events put-rule
--name "schedule-e2e-suite"
--schedule-expression "rate(5 minutes)"
aws events put-targets
--rule "schedule-e2e-suite"
--targets "Id=1,Arn=arn:aws:lambda:eu-central-1:123456789012:function:e2e-suite"
Now we have our environment up and running: our lambda function will get executed every 5 minutes. The only thing we need now is the code we run!
Create the first test scenario
Our test scenario will do the most important job in the world: making sure that
this blog is up and running! In this example we assume the blog is available
if it returns a 200 OK HTTP status code on the root page:
resp, err := http.Get("https://akarasz.me")
if err != nil {
fail("unexpected error: %v", err)
return
}
if resp.StatusCode != 200 {
fail("unexpected status code: %d", resp.StatusCode)
return
}
success()
That’s it. We send an HTTP request to the URL, then based on the outcome we either:
- fail because an unexpected error happened during the request
- fail because the response code was not what we expected
- mark the test as a success.
The only thing remained is to make sure the outcome of the testing reaches the on-call person of the operations team.
Integrate with the alerting service
In our example for orchestrating operational tasks we use PagerDuty, which describes itself as an operation management platform. While the list of the available features is pretty long, here we focus on a single one: it’s capability to trigger or resolve alerting events for various issues in our service. In case of an issue our process is simple:
- an outage happening in our service
- our test suite detects the issue
- triggers the alert in PagerDuty (by calling the
fail()method) - the on-call person gets notified and gets on fixing the issue.
When the responder fixes the issue - or the issue resolves itself, eg.
recovering from a network spike - the alert gets resolved automatically by the
test suite on the next test run: when all conditions are set the test
finishes with a success() call.
Both success() and fail() has a similar implementation - creating an
V2Event and calling PagerDuty’s API with it:
e := &pagerduty.V2Event{
RoutingKey: pdApiKey,
DedupKey: "e2e",
Action: "trigger",
Payload: &pagerduty.V2Payload{
Summary: "e2e failed!",
Severity: "critical",
},
}
client.ManageEvent(e)
- The
RoutingKeyfield has our integration API key for the service in PagerDuty, here is how to acquire one. - In the
DedupKeyfield we set a value that’s unique for the scenario we are testing - PagerDuty relies on this field to link this new event to an already existing one: if we send two events with differentDedupKeywe’ll have two separate events while if we send one with the same key we update the previous one. When the issue resolves this has an important role, because our alert will get resolved by sending a resolved event with the sameDedupKey. Actionis to define the current state of the event.- We can also add details to the
Payloadfield to help the job of the responder - in our case we can use the value we calledfail()with.
By using this piece of code, now we are able to manage alerts. 🎉
Conclusion
You can find the final code in this gist.
So to sum it up, in this post we saw how to
- built a simple end to end testing solution for our public API
- schedule lambda executions
- integrate with PagerDuty on their EventsV2 API.
Happy testing!