Recently I had to pay some tech debt for a piece of software that did not have it’s fair share of love in the past years: while it gets fresh features frequently the tests are quite neglected, thus refactoring takes an awful lot of time. Also, considering the state of the code and the level of over-engineering it suffered, our team already decided to split the service into smaller pieces in the near future - so the challenge is on: how to fix the issue with the least time invested, but with the current engineering best practices?
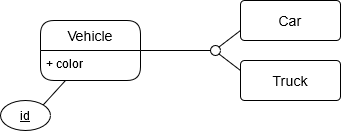
This is the entity relationship diagram of the related tables, simplified (and from a more common domain):
Adding a single unique constraint to a postgres table is simple:
alter table
vehicle
add constraint color_key unique (color);
Adding a composite unique constraint in postgresql is not difficult either:
alter table
vehicle
add constraint color_make_key unique (color, make);
But we have three tables here: Vehicle has the attributes that are
common and both Car and Truck have their own attributes. In our example
there is a color attribute that is shared and we want to have a constraint
that prevents same typed vehicles with the same color.
Writing tests first
Having automated tests checking the expected behavior is just as handy as writing unit tests for simple functions. For integration tests like this I like to use containers of the target service that get initialized within the test itself, making sure that we are as close to the actual production system as we can.
The gist of the test is the following:
startTestContainer()
conn := createPgConnection()
applySchema(conn, "schema.sql")
insertCar(conn, "red")
insertTruck(conn, "red")
err := insertCar(conn, "red")
// expect error
After we initialize our environment we add a red car and truck to the freshly created database; with this in place we expect an error if we try to insert another red car into the database. You can find the working test here.
Running the test now fails as expected at this point.
--- FAIL: TestUnique (4.01s)
unique_test.go:35: inserting the second red car should fail
unique_test.go:40: inserting the second red truck should fail
FAIL
FAIL akarasz.me/test 4.101s
FAIL
Looking for a solution
As usual, there are numerous ways for dealing with this issue - our goal is to find one suiting our interests most efficiently; and this is the exact reason why redesigning the data structure is not the path we take: it would just take too much time.
With single tables what we would use is a unique constraint on the schema definition - maybe postgres already have a way for defining unique constraints on joined tables?
The UNIQUE constraint is out, it doesn’t even have the syntax to list
attributes from multiple tables. The CHECK constraint is looking more
promising: we can define custom expressions by using it. Unfortunately this has
it’s limitations as well: all attributes must come from the same table.
Next thing we can try is to have a function that we call automatically for every create or update command; execution (create or update) should fail when the new item would violate our unique constraint - give this a try!
Implementing the trigger
First of all we need a function that we can pass as a trigger:
create function unique_check() returns trigger as $$
begin
if ... then
raise exception 'not unique';
end if;
return NEW;
end;
$$ language plpgsql;The idea is that unless our expression is false (in the highlighted line) we
return the same data (NEW) unmodified for the database to process - if our
expression fails we raise an exception causing the data insertion to fail.
With a unique check what we want to make sure that there is no row already exists in the database with the same attributes - in our case this means we don’t have two cars with the same color. The following expression will list all the cars that has the same color as car #42:
select
*
from
vehicle
join vehicle as this on this.color = vehicle.color
join car on car.vehicle_id = vehicle.id
where
this.id = 42 and
vehicle.id != this.idBy combining the trigger skeleton and the query we get final function and trigger definition:
create or replace function unique_car_check() returns trigger as $$
declare
total int;
begin
select
count(*)
into
total
from
vehicle
join vehicle as this on this.color = vehicle.color
join car on car.vehicle_id = vehicle.id
where
this.id = NEW.vehicle_id and
vehicle.id != this.id;
if total > 0 then
raise exception 'already has a car with color';
end if;
return NEW;
end;
$$ language plpgsql;
create trigger
car_unique_vehicle
before insert or update
on car
for each row execute procedure unique_car_check();After repeating the same for the trucks the final schema file looks like this. Executing the tests will show that we achieved our goal:
ok akarasz.me/test 5.899s
Conclusion
In this post we
- had some automated tests for validating database behavior
- went through the process to pick the best solution for our requirements
- and created a custom trigger function for our tables.
Keep in mind, that repeating a similar hack in your case might not be the desired solution. By normal circumstances - as I already mentioned before - I would’ve suggested to revisit the design of the schema and have a more fitting data structure for the constraints we have; it spares a lot of headache for the engineers on the long run.
You can find the final code here.