Serverless architecture is a recent interest of mine; in the last couple of weeks I was involved in a new project at work that’s running entirely in the AWS cloud. Since my most hands-on experience with the cloud so far was having a few virtual machines at Digital Ocean, I figured it’s best if I start exploring the Amazon Web Services at the beginning: with the ramp-up guide for the entry-level AWS certification, “Cloud Practicioner”.
Needless to say my motivation for finishing the entire course was dropping fast, but it was just enough for me to read through the (currently) 72 pages of “Overview of AWS” whitepaper listing all the available AWS services with a short (and very useful 🙄) marketing pitch. While reading the guide I realized, that the “lambda” service I heard about first a few years ago (and that time after a quick research I classified it as “useless”) is actually a quite interesting and useful tool when combined with additional services in the portfolio.

So what should one do after reading a few pages about something new and shiny? Tries it out in practice!
This item is the first one on a series called Pajthy to AWS where I try to capture the process of migrating one of my open-source pet projects into a serverless setup in AWS.
Pajthy, the pet project
After a quick lookin' around, my choice for tinkering was one of my recent projects, a simple voting tool for our scrum grooming session at work called pajthy; it’s an ideal choice, since
- it’s a full stack app, so by migrating this single service I’ll be able to test the widest range of tools in AWS
- the code base is quite small. my thinking was: there could not be too many issues while migrating if there is no much code at all 🧠
- pajthy does not use external dependencies (yet), all dealt internally right now - I have another project using the same flow and architecture, there I have a Redis implementation for storage and rabbitMQ for dealing with events. So if this experiment turns out successfully I might continue with that other app. We’ll see…
- and last, user base of pajthy is close to zero, nobody will cuss at me if there are downtimes.
Frontend is a simple SPA built in React. You can find the frontend code here.
The backend itself consists of three module:
- handler changes the state for the vote sessions based on incoming requests. The backend has a neat (and overcomplicated) REST interface to let users interact with
- store takes care of saving and loading sessions; at the time being it’s just an in-memory map of sessions for IDs
- event makes sure that every user gets notified about the actions taken who subscribed via websocket.
A flow for a randomly selected action (basically the same for every one of them):
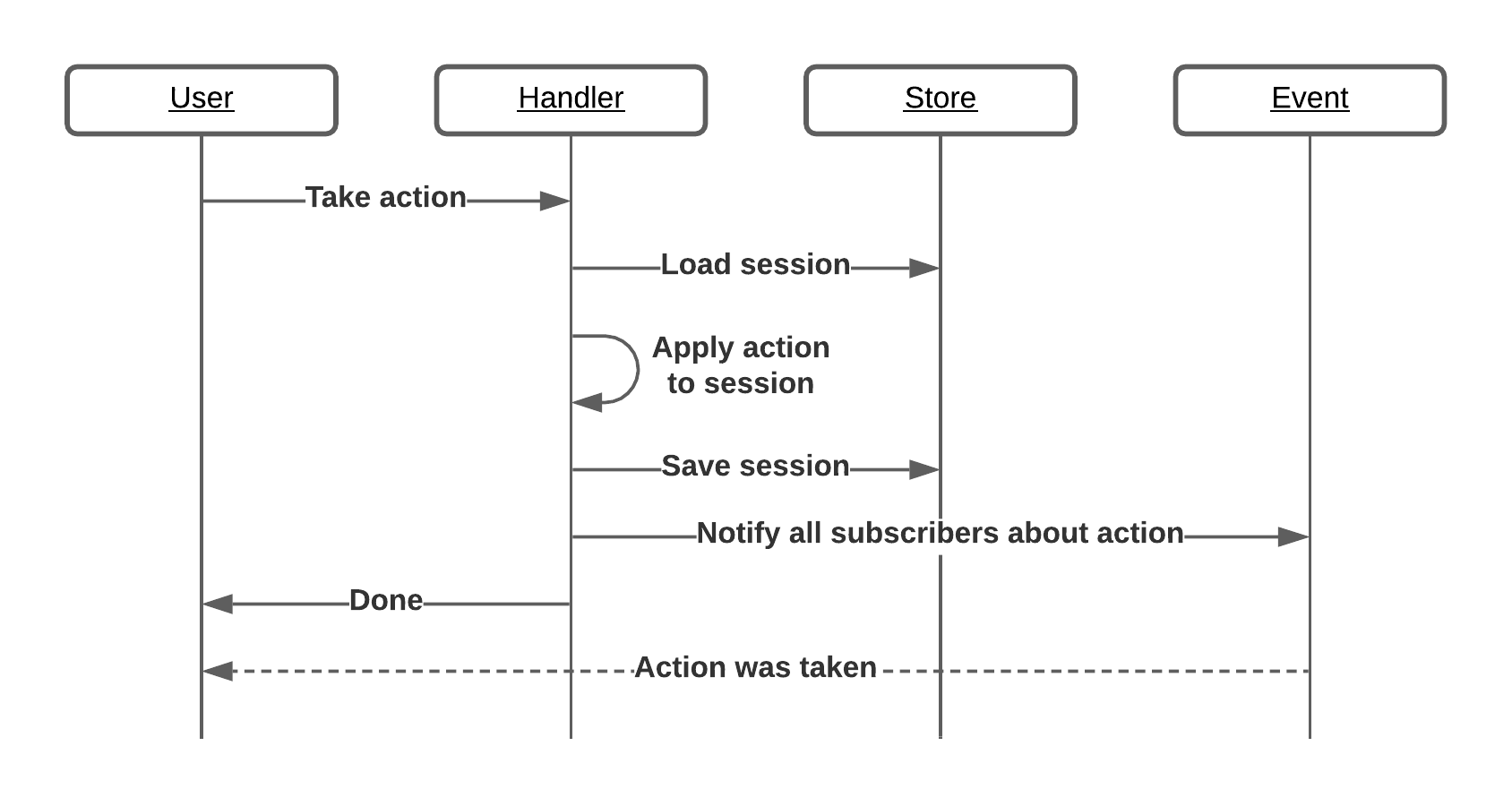
There are two user roles in the app: controllers and voters. A controller can start, stop or reset the voting and kick voters out from the session. A voter can vote when the session is active. Easy as promised, right?
Backend code is here.
The plan
Instead of doing it all-in, I wanted to take an approach of trying to avoid the
vendor lock-in that would make it impossible to move the code easily between
cloud providers (or back to on premise). For achiving this goal I want to
handle the core codebase as a black box (in our case it’s the handler module
containing the business logic and the interface part for both store and
event).
The best way (I figured) to ensure that I’m still haven’t changed things inside of the black box is by making sure after every step that
- frontend in AWS can still communicate with a non-AWS backend
- backend in AWS can still be used by a non-AWS frontend
and when I’m talking about non-AWS backend I mean the current, in-memory store and events. I will test these cases repeatedly during the migration.
So after a quick thinking through my plan was the following
- move the whole frontend into S3
- wrap the backend service into a lambda function, wire it into the API gateway
- use a dynamoDB implementation instead of the in-memory store
- push the events into SNS and hook them up onto a Websocket API in API gateway.

Keep in mind, these were the initial plans, the first iteration without any on-hands AWS experience, just five minutes after I finished the reading about the services, building only on my assumptions. And as we all know well, nothing is ever as easy as it seems first…
The end? This is it?
No worries, this is obviously not the end of the series. In the following posts I will to go through of each item of my plan, showing the obsticles I was facing and the things I learned while was solving them. Plus probably a brain dump here and there since I like to do those anyways.