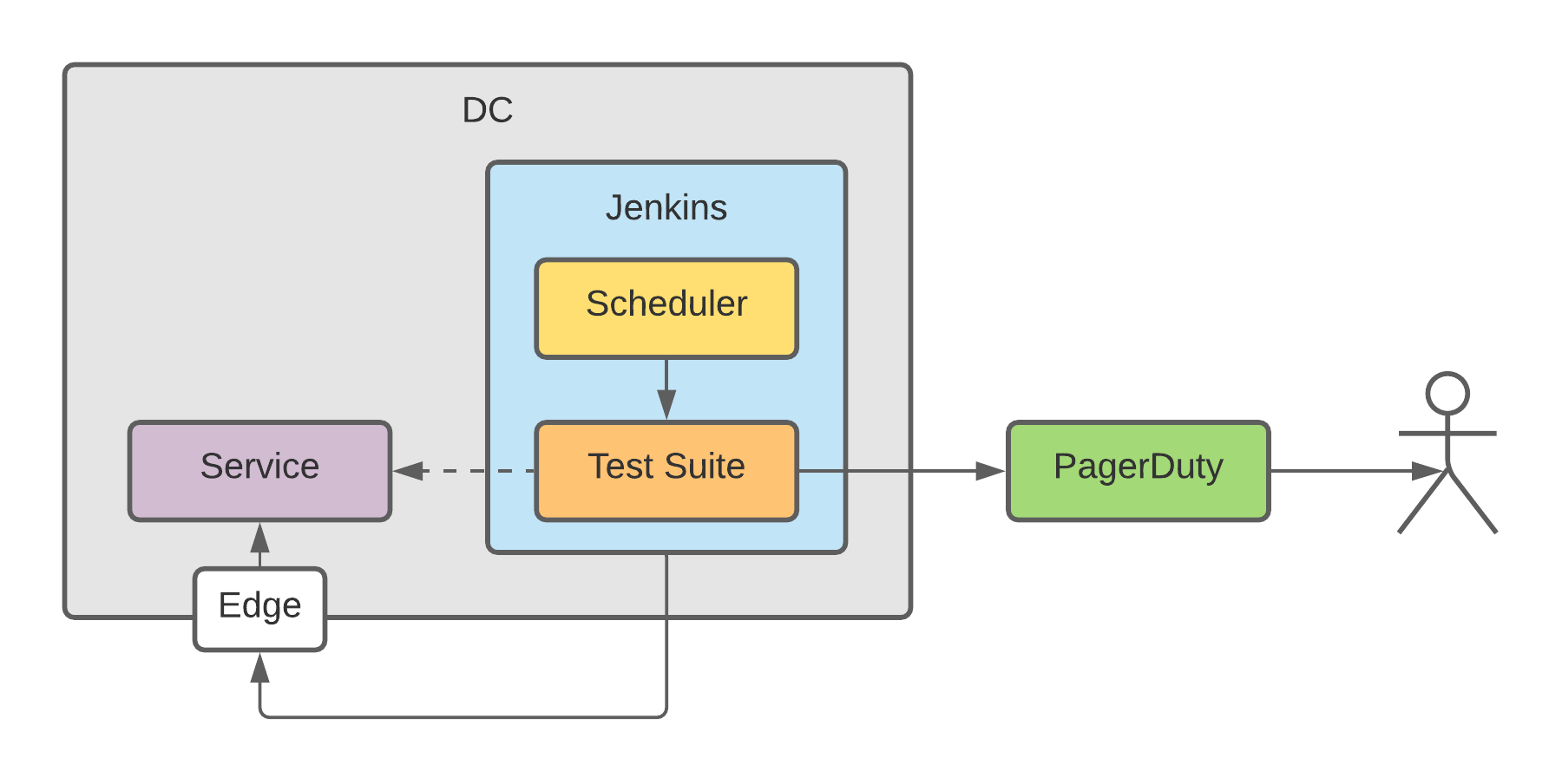
Cussing-free git commits
A few months ago I got a message from a random engineer on the company slack; he
told me that he reviewed one of my pull request, and I might want to go through
my code again, since I left some “inappropriate” debug logs there. I immediately
checked what he could’ve mean, and I found the println() with a content that
was unmistakably created out of sheer rage and desperation caused by hours of
an unsuccessful bug hunting session. Unless you have a temper of a zen-master,
I bet you know what kind of bug I’m talking about.
I prefer to prevent “accidents” like this one - after all, this is what agile is about, right? So I started to look for a solution - then ended up at git hooks pretty fast. However, with git hooks we have basically two options:
- run the same
pre-commithook for every repository and skip the repo-defined hook (follow the red arrow)
or
- copy my
pre-commithook to every repository I work, worked and ever will work with (go as the green arrow). Neither is a good choice. 😕
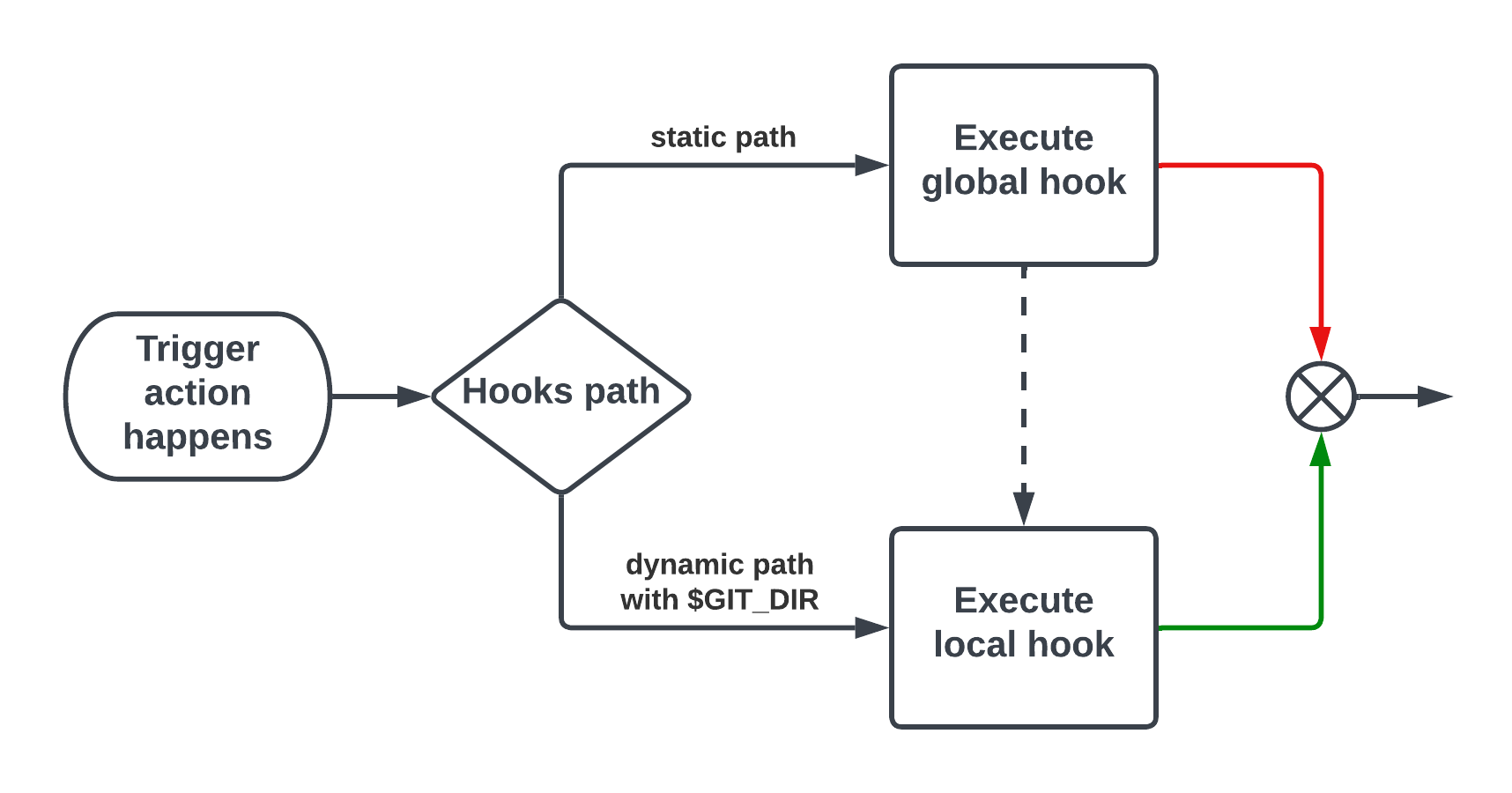
What I want instead is to run both, basically to go through the dashed arrow. And there is a fairly simple way to achieve this.